
Interesting techniques for working with dates
A while ago Gary wrote to the php-dd email list with this interesting question:
> From: Garry > Subject: Date operations. > > Hi All, > > I have a problem working out a suitable algorithm either in PHP or MySQL. > > Basically I have a DB that keeps track of breeding records. Each record > has a paired data, and a split-up date. > > I need to generate some statistics to work out average numbers of pairs > per month, averaged on a daily basis, for a given start and stop date, > typically a year or year-to-date. > > All the algorithms I can think of are messy, where I have to loop through > all the breeding records for every day of the year, and count how many > pairs are breeding by seeing if the date is between the start and stop > dates, and then average that on a monthly basis. I can't see > that scaling very well, as there might be several hundred breeding records > for a given year, multiplied by 365 days. > > Has anyone any hints/pointers for an efficient way to do this? > > Regards, > Garry. >
His schema looked like this:
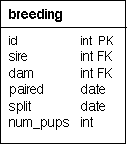
Where 'sire' and 'dam' were keys to the dog table and 'id' was the primary key of this table. The report he wanted most was the daily average of active breeding pairs by month. He had tried several methods of looping through this table to count the pairs by day but had found it to be very messy. Fortunatly there is a better way.
The period table is a table that has every day over the range of time you care about. It can have other attributes which will make life simpler (more on that later on). In it's simplest form it has 'id' and 'date' columns and one row for every day. It could be modified to have one row fro every hour or second; conversly one row for every week, month or year this all depends on the level of granularity you need, Most typically it is one row per day. We also add columns for day, month and year; this saves us from having to parce up the date over and over again.
| Sample period table data | ||||
|---|---|---|---|---|
| id | p_date | p_day | p_month | p_year |
| 305 | 2005-1-1 | 1 | 1 | 2005 |
| 306 | 2005-1-2 | 2 | 1 | 2005 |
| 307 | 2005-1-3 | 3 | 1 | 2005 |
| 308 | 2005-1-4 | 4 | 1 | 2005 |
| 309 | 2005-1-5 | 5 | 1 | 2005 |
| ... | ... | ... | ... | ... |
We modify the schema to make the dates in the 'breeding' table foreign keys in the 'period' table. Now we can do the report Gary was looking for in a single SQL statement. Let's build the statement in pieces so we can see what's happening.
First on any given day (for a specific period.id) show all the currently breeding pairs.
SELECT b.id, b.sire, b.dam, p.p_date FROM breeding b, period p WHERE b.paired <= p.id AND b.split >= p.id AND p.id = 307
As we can see this would return all rows from 'breeding' that were paired on or before January 3, 2005 and were split on or after January 3, 2005. Now lets return the daily total for January 3, 2005.
SELECT count(b.id), p.p_date FROM breeding b, period p WHERE b.paired <= p.id AND b.split >= p.id AND p.id = 307 GROUP BY p.p_date
At this point the GROUP BY is not strictly necessary because we know that the p.id is restricting the p.p_date to only one value. But if we change the p.id = 307 to p.month = 1 AND p.year = 2005 we will get the daily totals for each day in January 2005 (NOTE: always remember to include a year in this kind of query - it works without the year now because there is only one year in the database but next year you will get strange results).
SELECT count(b.id), p.p_date FROM breeding b, period p WHERE b.paired <= p.id AND b.split >= p.id AND p.month = 1 AND p.year = 2005 GROUP BY p.p_date
Still not quite there. We wanted the daily average by month; we'ge got the daily total for a month. We could run this query for each month and average these numbers relitively easily but I said 1 SQL query. Watch this:
SELECT count(b.id)/count(distinct(p.day)), p.month, p.year FROM breeding b, period p WHERE b.paired <= p.id AND b.split >= p.id AND p.year = 2005 GROUP BY p.month, p.year
Not only does it work but your server didn't even work up a stresss in figuring it out. But wait, you get so much more with this strategy. Read on.
One characteristic of SQL is if you join two a tables you will only get results where the rows match; if you had a 'customer' and an 'order' table and you tried to do a report on how many orders each customer had placed last year you would not get any of the customers who had no orders last year. This might be what you want then again it hides something that's very important. If, for example, you're trying to increase your sales you'll probably want to look at customers who have not bought anything and try to figure out why not.
In the above example there is a problem. I assumed there was always at least one pair every day. If there is the query works as described but if there is a month where for the first 15 days there were 2 pair breeding then there no pair breeding for the last 15 days this query would show that there was a daily average of 2 when it should have been 1.
The solution is to use an OPEN JOIN (in MySQL it is often called a LEFT JOIN or RIGHT JOIN; these are similar but the tables are in a different order). The idea is give me every row from table A and join it to table B if you can but if you can't still give me the row from A. In our case we want every row from the period table because each single row is a day. So our query becomes:
SELECT count(b.id)/count(distinct(p.day)), p.month, p.year FROM breeding b RIGHT JOIN period p ON b.paired <= p.id AND b.split >= p.id WHERE p.year = 2005 GROUP BY p.p_month, p.p_year
Now how much would you pay for this solution? But wait there's more: You can add any kind of attribute to the period table you wish. This is amazingly powerful.
I once worked for a company that decided that the fiscal month and quarter would always end on the last working Friday of that month. Handy for some I suppose but none of the built in date functions work like that. Even more fun upon occasion they wold decide that if that Friday was a Holiday they might use Thursday.
It can be very difficult to code around this but if we add columns to the period table with the fiscal month and quarter we can assign a date to any fiscal month and quarter we want; even go back and change them if we got it wrong.
Imagine adding a column for phases of the moon into our database. Are there more dogs fertile during a full moon? I have no idea but I know how to write that query.
ALTER TABLE period ADD COLUMN moon_phase enum('full', 'new', 'quarter', 'three_quarter');
SELECT count(b.id)/count(distinct(p.day))
FROM breeding b RIGHT JOIN period p
ON b.paired <= p.id
AND b.split >= p.id
WHERE p. moon_phase = 'full'
GROUP BY p_date
So there you go - try it, enjoy and if it help you out or you have questions send me a note.
Frank